Rozpoznawanie tekstu OCR w dokumencie zapisanym w PDF

Typowe oprogramowanie służące do skanowania dokumentów tworzy obraz danego dokumentu. Nie zapisuje tekstu w postaci edytowalnej, który można przeszukiwać. Jeśli użytkownik chce tworzyć inteligentne dokumenty, które może edytować, wyszukiwać, ponownie wykorzystywać lub udostępniać w swoim archiwum, wówczas będzie potrzebował innego narzędzia. W takiej sytuacji pomocne jest optyczne rozpoznawanie znaków - OCR.
OCR przekształca skany w edytowalne dokumenty z możliwością przeszukiwania
Dzisiejsze silniki OCR są zaaawansowanymi narzędziami, które staraja się wykryć wszystkie znaki w dokumencie. Jednak z natury takie rozpoznanie nie jest skutecznie w 100%. Często zależy to od wielu czynników np. jakości zeskanowaniego dokumnetu, rodzaju oprogramowania OCR i wielu innych. Co oznacza, że należy sprawdzić wynikowy dokument. Można przejrzeć cały dokument, jednak to wymaga dużo czasu. Są jednak pewne elementy, o których warto wiedzieć, czy wymagają poprawy.
Przekształcenie ukrytego tekstu ("hidden" text OCR), w tekst, który można wyświetlić
Z technicznego punktu widzenia taki tekst nazywany jest ukrytym tekstem ("hidden text") w pliku PDF tak jak użytkownik zwykle widzi obraz.
Edytory PDF są "ukryte" lub "siedzące" za obrazem.
Zazwyczaj pierwszą czynnością jest skopiowanie i wklejenie tekstu z wynikowego pliku PDF do programu Word w celu jego odczytania lub edycji. Jest jednak na to lepszy sposób.
Program Foxit PhantomPDF oferuje przydatną funkcję, która pozwala pozostać w edytorze PDF. Wystarczy kliknąć, w opcję Text Viewer, aby zobaczyć tekst OCR.
W programie Foxit używająć Text Viewer można pracować na wszystkich dokumentach PDF w trybie czystego tekstu. Takie działania umożliwia łatwe ponowne wykorzystanie tekstu rozproszonego między obrazami i tabelami. Dodatkowo narzędzie działa jak Notatnik.
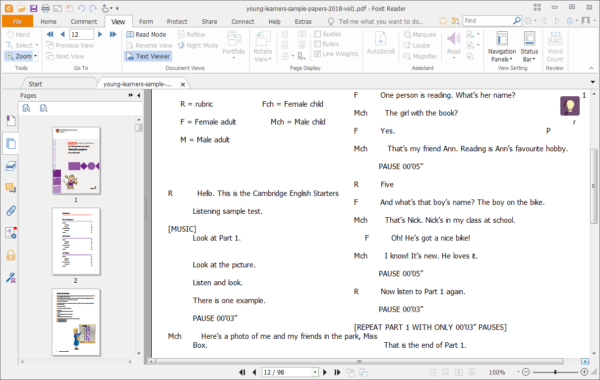
- Wybrać opcję: View -> Document Views ->Text Viewer
- Nacisnąć klawisze klawiatury CTRL + 6