Optymalizacja skanów w Foxit PhantomPDF
Niektóre z zeskanowanych dokumentów, szczególnie jeśli zawierają obrazy i kolorowe czcionki mogą okazać się zbyt duże, by można było je bezproblemowo załadować lub wysłać e-mailem.
Foxit PhantomPDF oferują dwa sposoby optymalizacji zeskanowanych dokumentów: rozpoznawanie tekstu i kompresja.
Aby przetwarzać dokument można po prostu umieścić go w programie, jednak niemożliwe będzie zaznaczenie tekstu, ponieważ tak umieszczony plik nie zawiera żadnych informacji tekstowych. Mimo, że program od razu konwertuje plik na PDF, należy podać brakujące informacje tekstowe przechodząc do File, a następnie Optimize Scan. Wówczas zostanie wyświetlony szereg różnych opcji.
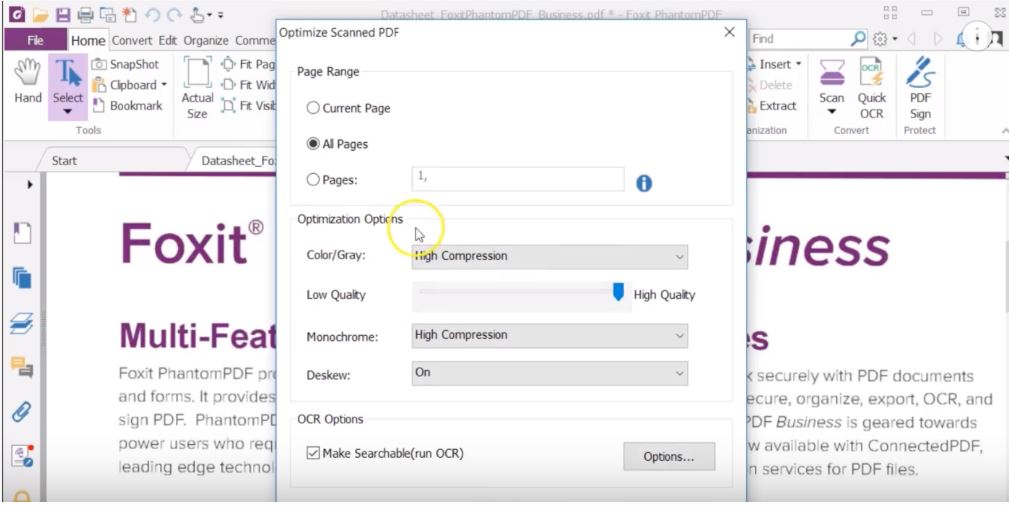
Najpierw można zaznaczyć zakres strony do przetworzenia.
Następnie pojawi się kilka opcji dla optymalizacji kompresji dotyczących m.in. tego czy dokument jest w kolorze czy w skali szarości.
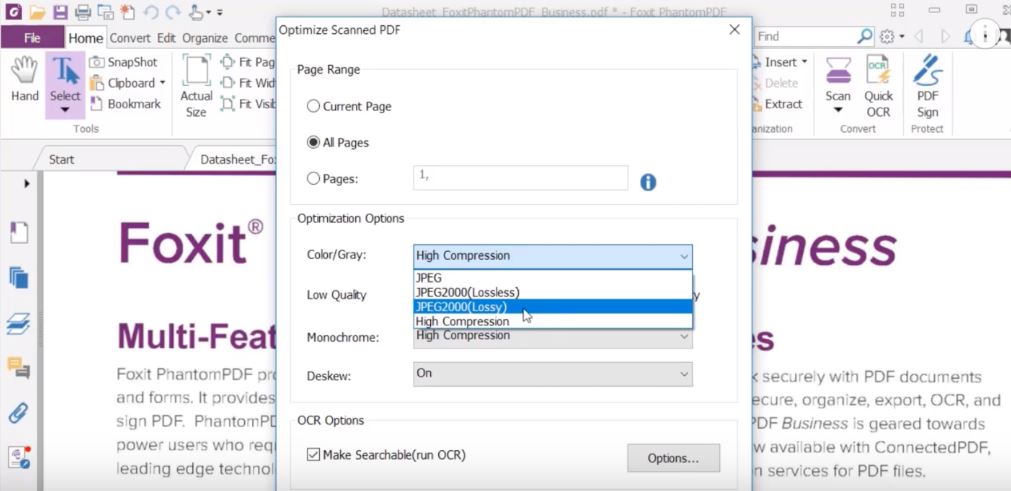
Dla obrazu kolorowego dostępnych jest kilka kodeków. Najprostszym jest zwykły JPEG, ale można wybrać też najnowszy JPEG 2000 z kompresją stratną lub bezstratną. Bezstratna nie powoduje utraty informacji z obrazu, obraz zamieniany jest piksel po pikselu. Natomiast stratna oznacza, że w obrazie mogą się pojawić pewne zmiany, jednak w taki sposób, że nie powinny być zauważalne dla ludzkiego oka.
Za pomocą suwaka i opcji kompresji można regulować jakość dokumentu. Silna kompresja będzie starała się dzielić zwartość strony na osobne warstwy i kompresować jest osobno, zachowując czytelność tekstu w dokumencie do OCR (optycznego rozpoznawania znaków). Dostępne są też opcje dotyczące języka oraz czy tekst ma być edytowalny.
Kliknięcie OK spowoduje rozpoczęcie przetwarzania. Dla dokumentu zostanie przeprowadzone OCR i kompresja. Po tych operacjach tekst można zaznaczać, ponieważ informacje o nim zostały wygenerowane i dołączone do pliku PDF.
Zapisywany plik jest około 20 razy mniejszy od oryginału co znacznie ułatwia udostępnianie go i przechowywanie.