Foxit PhantomPDF – stosowanie OCR dla wielojęzykowych dokumentów
OCR (Optical Character Recognition) czyli optyczne rozpoznawanie znaków to technologia pozwalająca na przekonwertowanie dokumentów papierowych czy obrazów na tekst w formie cyfrowej, możliwy do odczytu maszynowego. OCR najczęściej wykorzystywane jest do skanowania dokumentów drukowanych, w celu utworzenia ich kopii elektronicznej, ale może je także zastosować w istniejących dokumentach elektronicznych takich jak pliki PDF.
Podczas przeprowadzania operacji OCR na pliku lub wielu plikach PDF w programie Foxit PhantomPDF, możliwe jest wybranie więcej niż jednego języka do rozpoznania. Umożliwia to wykrycie wielu różnych języków w jednym dokumencie. Dzięki temu można utworzyć przeszukiwalny plik PDF z zeskanowanego pliku PDF lub obrazu zawierającego tekst w wielu językach. Taka możliwość oszczędza zarówno czas i wysiłek włożony w konwertowanie dokumentów papierowych.
Rozpoznawanie wielojęzykowego tekstu w programie PhantomPDF:
Aby ze zwykłego dokumentu statycznego zawierającego więcej niż jeden język, utworzyć przeszukiwalny plik PDF należy:
1.Otworzyć pasek narzędzi Konwersji w jeden z następujących sposobów:
3. W oknie dialogowym Select OCR Engine należy wykonać następujące kroki:
Przeprowadzanie operacji OCR dla wielu dokumentów wielojęzykowych jednocześnie.
Aby przeprowadzić rozpoznawanie tekstu w wielu plikach PDF należy:
1. Otworzyć pasek narzędzi Konwersji w jeden z następujących sposobów:
3. W oknie dialogowym OCR Multiple Files należy wykonać następujące kroki:
Podczas przeprowadzania operacji OCR na pliku lub wielu plikach PDF w programie Foxit PhantomPDF, możliwe jest wybranie więcej niż jednego języka do rozpoznania. Umożliwia to wykrycie wielu różnych języków w jednym dokumencie. Dzięki temu można utworzyć przeszukiwalny plik PDF z zeskanowanego pliku PDF lub obrazu zawierającego tekst w wielu językach. Taka możliwość oszczędza zarówno czas i wysiłek włożony w konwertowanie dokumentów papierowych.
Rozpoznawanie wielojęzykowego tekstu w programie PhantomPDF:
Aby ze zwykłego dokumentu statycznego zawierającego więcej niż jeden język, utworzyć przeszukiwalny plik PDF należy:
1.Otworzyć pasek narzędzi Konwersji w jeden z następujących sposobów:
- Wybrać Tools, następnie Convert.
- Na pasku Common Tools kliknąć symbol dwóch strzałek w dół i wybrać Convert.
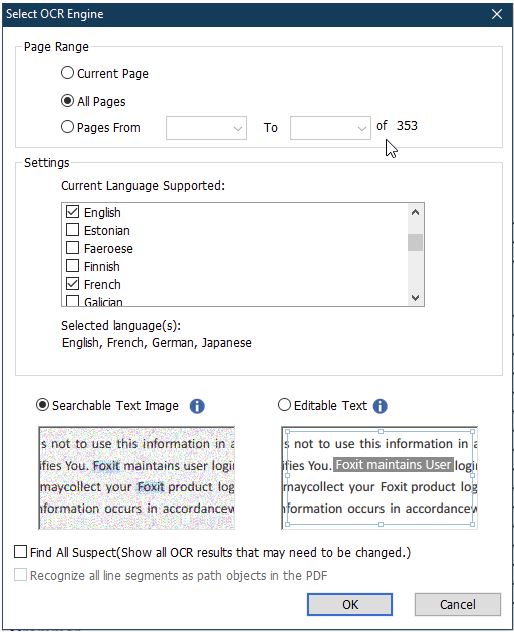
3. W oknie dialogowym Select OCR Engine należy wykonać następujące kroki:
- Określić obszar strony do przetworzenia przez OCR
- Wybrać język/języki występujące w dokumencie
- Wybrać typ wyjściowy: Searchable Text Image - przeszukwialny obraz tekstowy pozwalający na przeszukiwanie tekstu lub Editable Text czyli edytowalny tekst.
- Zaznaczyć opcję Find All Suspects, wyświetlającą wszystkie wyniki operacji OCR, które mogą wymagać poprawy.
- Kliknąć OK, aby uruchomić rozpoznawanie tekstu.
Przeprowadzanie operacji OCR dla wielu dokumentów wielojęzykowych jednocześnie.
Aby przeprowadzić rozpoznawanie tekstu w wielu plikach PDF należy:
1. Otworzyć pasek narzędzi Konwersji w jeden z następujących sposobów:
- Wybrać Tools, następnie Convert.
- Na pasku Common Tools kliknąć symbol dwóch strzałek w dół i wybrać Convert.
3. W oknie dialogowym OCR Multiple Files należy wykonać następujące kroki:
- Kliknąć Add Files i wybrać Add Files (dodaj pliki), Add Folder (dodaj folder) lub Add Open Files (dodawanie otwartego pliku).
- Ustalić kolejność plików za pomocą przycisków przesuwania w górę i dół.
- Kliknąć Remove, aby usunąć z listy pliki, które nie mają zostać przetworzone.
- Kliknąć Output Options, aby wybrać docelowy folder zapisu i wybrać nazwę nowego pliku lub nadpisać istniejący.
- Kliknąć OK.